
Artículo Premium
#5 Guía definitiva sobre los 8 modelos de ChatGPT: qué versión utilizar y por qué
¿Qué modelo elegir?
Esta es la gran pregunta. Por defecto el modelo de ChatGPT es el 4o y que se lanzó en mayo de 2004. Mi recomendación es utilizar los siguientes modelos en una asesoría contable, fiscal y laboral:
¿Es importante elegir bien el modelo cuando estamos creando un Agente IA?
Al crear un agente de inteligencia artificial así como todos los flujos de procesos tú puede elegir un modelo para generar las respuestas. Por tanto, es necesario conocer bien las diferencias entre unos y otros.
En las siguientes imagenes podéis ver, dentro de mi CRM, que al crear un prompt para el agente IA tengo la opción de elegir el modelo. En el caso de Copilot Studio, comoexplicaba David Hurtado en el último videoblog, es igual. Microsoft tiene en su repositorio más de 1.800 modelos.
Esta es la gran pregunta. Por defecto el modelo de ChatGPT es el 4o y que se lanzó en mayo de 2004. Mi recomendación es utilizar los siguientes modelos en una asesoría contable, fiscal y laboral:
- Modelo 4o (GENERAL). Para conversaciones casuales, brainstorming o tareas que no requieren una precisión extrema en el formato o un contexto muy largo
- Modelo 4.1 (VOLUMEN DE DATOS) Necesitas procesar grandes volúmenes de texto o datos. Su ventana de contexto de 1 millón de tokens es ideal para análisis de documentos extensos, bases de código, transcripciones largas, etc.
- Modelo o3 y 03-pro (RAZONAMIENTO) para descomponer problemas complejos en pasos lógicos, dedicando más tiempo y recursos computacionales para "razonar" a través de una tarea. Esto los hace excepcionalmente buenos en tareas que requieren inferencia, análisis y resolución de problemas.
¿Es importante elegir bien el modelo cuando estamos creando un Agente IA?
Al crear un agente de inteligencia artificial así como todos los flujos de procesos tú puede elegir un modelo para generar las respuestas. Por tanto, es necesario conocer bien las diferencias entre unos y otros.
En las siguientes imagenes podéis ver, dentro de mi CRM, que al crear un prompt para el agente IA tengo la opción de elegir el modelo. En el caso de Copilot Studio, comoexplicaba David Hurtado en el último videoblog, es igual. Microsoft tiene en su repositorio más de 1.800 modelos.
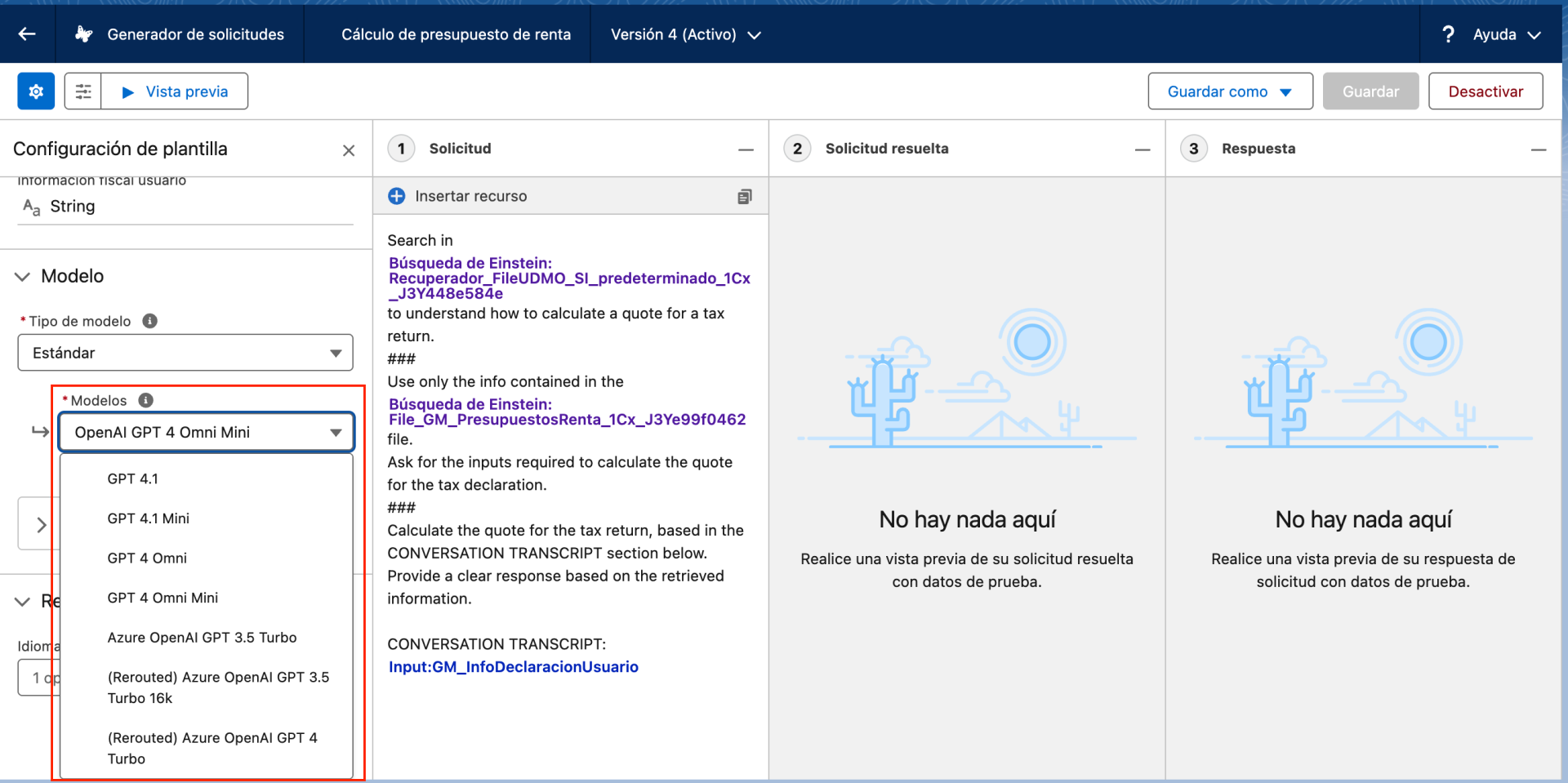
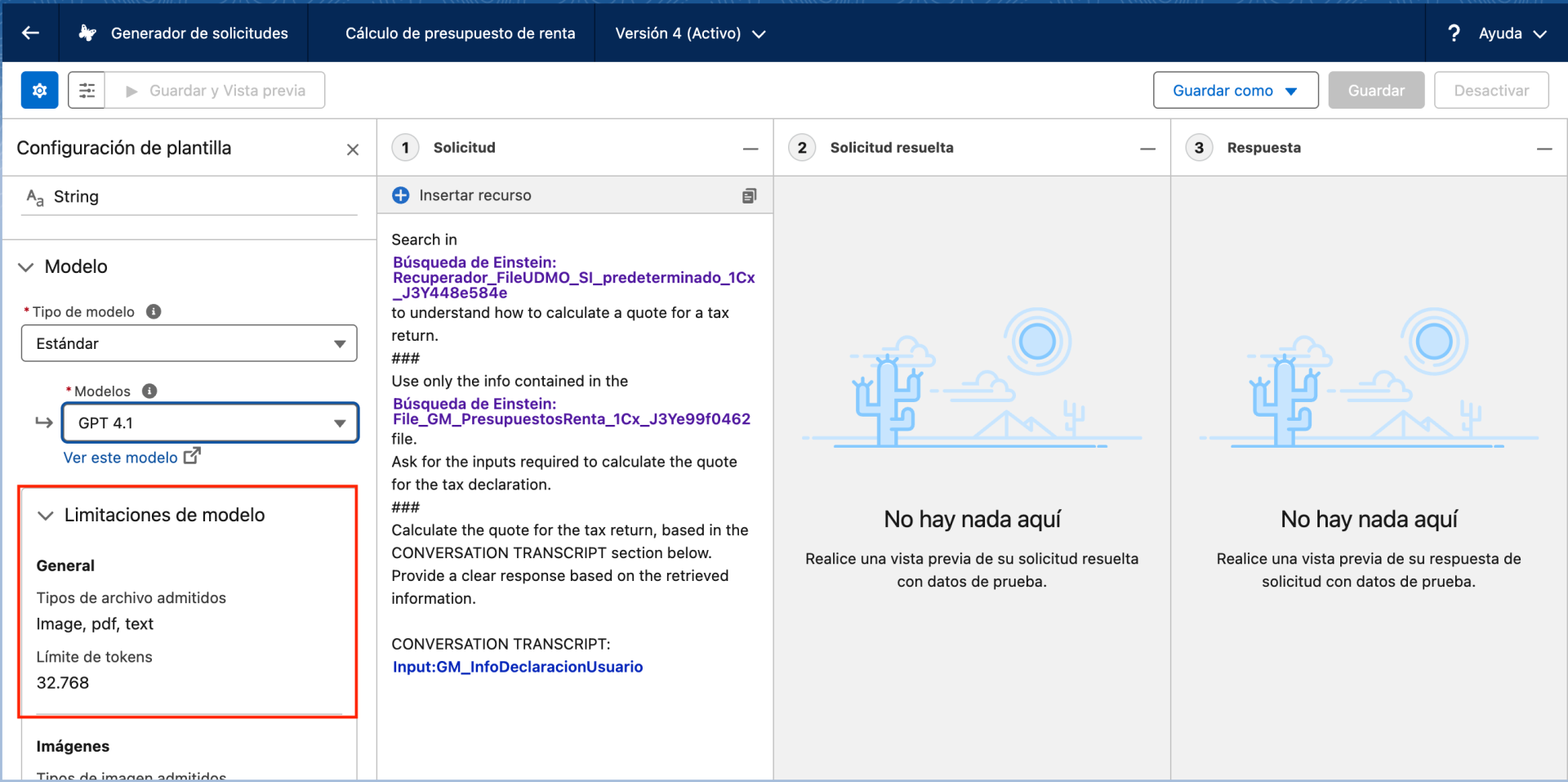
Si quieres profundizar más sobre los diferentes modelos de lenguaje de gran escala (LLM) que existen en el mercado te aconsejo que tengas en cuenta también los denominados SLM o Small Language Models.
Un SLM es, en esencia, un modelo de inteligencia artificial entrenado para comprender y generar lenguaje, pero con una arquitectura mucho más reducida que la de los LLM. La gran ventaja es que se permiten ejecutar en dispositivos locales, como ordenadores personales, móviles o servidores privados sin acceso a internet.Entre los modelos de SLM más destacados actualmente se encuentran Mistral 7B, Phi-2 (Microsoft), Gemma (Google) y LLaMA 2 7B (Meta). Muchos de ellos han sido liberados bajo licencias abiertas, lo que permite su implementación personalizada en entornos empresariales o en soluciones a medida, sin depender de proveedores externos. Esta apertura está impulsando una ola de innovación, donde cada vez más compañías optan por desarrollar sus propios agentes y asistentes inteligentes sobre estos modelos base.
Te aconsejo este artículo del periódico Expansión: El gran negocio de los modelos pequeños de IA.
¿Por qué ChatGPT tiene tantos modelos?
Piensa en ellos como si fueran herramientas en una caja de herramientas cada una diseñada para un propósito ligeramente diferente. A continuación se explican las razones principales:
Tabla comparativa
A continuación encontrarás un análisis exhaustivo, comparativo y estructurado de los ocho modelos disponibles a junio de 2025.
Un SLM es, en esencia, un modelo de inteligencia artificial entrenado para comprender y generar lenguaje, pero con una arquitectura mucho más reducida que la de los LLM. La gran ventaja es que se permiten ejecutar en dispositivos locales, como ordenadores personales, móviles o servidores privados sin acceso a internet.Entre los modelos de SLM más destacados actualmente se encuentran Mistral 7B, Phi-2 (Microsoft), Gemma (Google) y LLaMA 2 7B (Meta). Muchos de ellos han sido liberados bajo licencias abiertas, lo que permite su implementación personalizada en entornos empresariales o en soluciones a medida, sin depender de proveedores externos. Esta apertura está impulsando una ola de innovación, donde cada vez más compañías optan por desarrollar sus propios agentes y asistentes inteligentes sobre estos modelos base.
Te aconsejo este artículo del periódico Expansión: El gran negocio de los modelos pequeños de IA.
¿Por qué ChatGPT tiene tantos modelos?
Piensa en ellos como si fueran herramientas en una caja de herramientas cada una diseñada para un propósito ligeramente diferente. A continuación se explican las razones principales:
- Velocidad vs. Precisión: Algunos modelos son súper rápidos y económicos, ideales para un chat casual o para responder muchas preguntas sencillas en poco tiempo. Otros son más "pensadores", se toman más tiempo, son más caros, pero son increíblemente precisos y buenos para tareas complejas como razonar sobre problemas científicos o escribir código.
- Contexto (memoria): Los modelos también varían en cuánta información pueden "recordar" de una conversación o de un documento que les das. Algunos tienen una "memoria" limitada, mientras que otros pueden manejar documentos muy largos o conversaciones extensas. Esto se mide en "tokens" (piezas de palabras).
- Habilidades específicas: Algunos modelos están optimizados para ciertas tareas. Por ejemplo, hay modelos que son excepcionales para el razonamiento matemático o la programación (como algunos de la serie "o3"), mientras que otros son mejores para generar texto creativo o mantener una conversación fluida (como GPT-4o)
- El precio importa: Entrenar y ejecutar estos modelos es increíblemente costoso en términos de energía y recursos computacionales. OpenAI crea modelos más pequeños y eficientes (como los "mini") para que puedan ofrecer servicios a un costo mucho menor, haciendo que la IA sea más accesible para más personas y empresas. No siempre necesitas la inteligencia más potente y cara para una tarea sencilla.
- Velocidad de respuesta: Un modelo más grande y complejo puede tardar más en procesar una solicitud. Los modelos "mini" están diseñados para dar respuestas casi instantáneas, lo cual es crucial para aplicaciones en tiempo real (como asistentes de voz o chatbots que interactúan con muchos usuarios a la vez).
- Experimentación: Algunas versiones pueden ser "vistas previas" o modelos experimentales (como GPT-4.5 Preview) que se lanzan para que los desarrolladores y usuarios avanzados los prueben y den su opinión antes de que se conviertan en versiones más estables y ampliamente disponibles.
- Usuarios gratuitos vs. de pago: ChatGPT a menudo ofrece diferentes modelos o niveles de acceso a sus modelos en sus planes gratuitos y de pago. Los usuarios gratuitos pueden tener acceso a modelos más rápidos y económicos (como GPT-4o, o versiones "mini"), mientras que los suscriptores de pago tienen acceso a los modelos más avanzados y capaces, con menos limitaciones.
- Desarrolladores: Para los desarrolladores que usan la API de OpenAI (para integrar la IA en sus propias aplicaciones), tener una variedad de modelos les permite elegir el más adecuado para sus necesidades específicas, optimizando tanto el rendimiento como los costos de sus productos.
Tabla comparativa
A continuación encontrarás un análisis exhaustivo, comparativo y estructurado de los ocho modelos disponibles a junio de 2025.
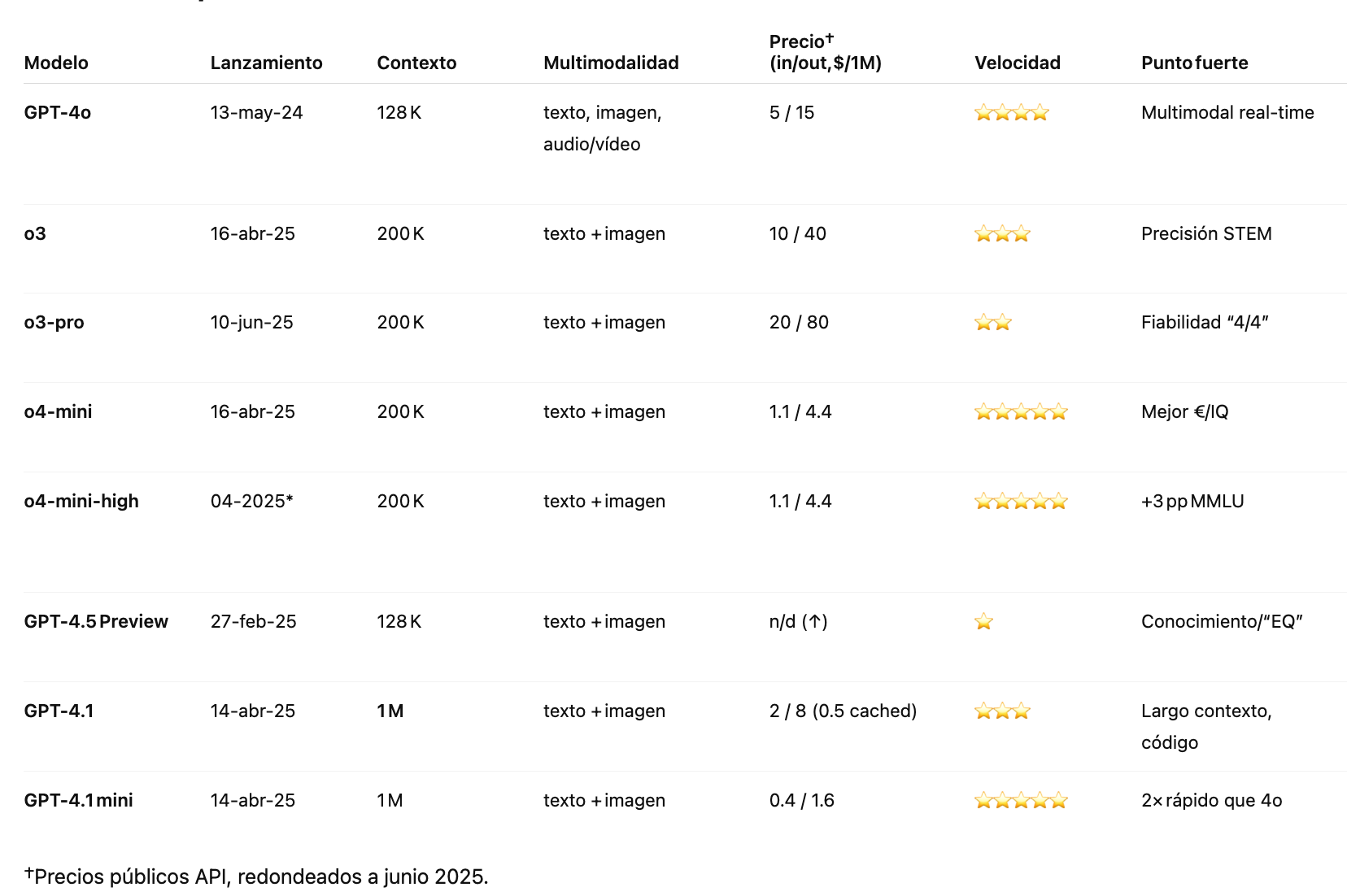
Modelo GPT-4o
GPT-4o, es el modelo que OpenAI lanzó en mayo de 2024. Este modelo marca un salto importante no tanto en el "qué" puede hacer, sino en cómo lo hace y con qué eficiencia.
Para empezar por lo más básico: la "o" en GPT-4o viene de "omni", y eso no es casualidad. Este modelo es capaz de razonar y responder de forma nativa con texto, voz e imagen, todo en tiempo real y sin necesidad de convertir internamente los datos a texto (que era lo que pasaba con modelos anteriores). Es decir, puedes hablarle, enseñarle una foto o preguntarle por escrito... y él lo procesa todo como si fuera lo mismo.
Esto cambia bastante la experiencia, sobre todo en ámbitos como la accesibilidad (porque puedes mantener una conversación hablada de ida y vuelta) o en situaciones donde necesitas combinar varios tipos de información: por ejemplo, mostrarle un gráfico y preguntarle qué está pasando, o enseñarle una factura y pedirle que te diga qué errores ve. Además, no sólo es más potente, sino mucho más rápido.
OpenAI afirma que GPT-4o responde en conversaciones de voz con una latencia promedio de unos 320 milisegundos. Es prácticamente instantáneo, muy parecido al ritmo humano. De hecho, tiene incluso la capacidad de interrumpir al usuario o responder con tono emocional (puedes pedirle que suene más alegre o más serio, por ejemplo).
GPT-4o, es el modelo que OpenAI lanzó en mayo de 2024. Este modelo marca un salto importante no tanto en el "qué" puede hacer, sino en cómo lo hace y con qué eficiencia.
Para empezar por lo más básico: la "o" en GPT-4o viene de "omni", y eso no es casualidad. Este modelo es capaz de razonar y responder de forma nativa con texto, voz e imagen, todo en tiempo real y sin necesidad de convertir internamente los datos a texto (que era lo que pasaba con modelos anteriores). Es decir, puedes hablarle, enseñarle una foto o preguntarle por escrito... y él lo procesa todo como si fuera lo mismo.
Esto cambia bastante la experiencia, sobre todo en ámbitos como la accesibilidad (porque puedes mantener una conversación hablada de ida y vuelta) o en situaciones donde necesitas combinar varios tipos de información: por ejemplo, mostrarle un gráfico y preguntarle qué está pasando, o enseñarle una factura y pedirle que te diga qué errores ve. Además, no sólo es más potente, sino mucho más rápido.
OpenAI afirma que GPT-4o responde en conversaciones de voz con una latencia promedio de unos 320 milisegundos. Es prácticamente instantáneo, muy parecido al ritmo humano. De hecho, tiene incluso la capacidad de interrumpir al usuario o responder con tono emocional (puedes pedirle que suene más alegre o más serio, por ejemplo).



¿Quieres ver todas las publicaciones?
Blog personal de José Pedro Martín
Últimas publicaciones

Comunidad apasionada por los Procesos y la Tecnología. Dirigido a asesores, consultores, gestores y abogados.
www.innovaciondespachos.com
www.innovaciondespachos.com